타겟 발굴 및 검증 에이전트
유전학, 생물학, 경쟁 환경까지 — 한 번의 실행으로 모든 유전자 타겟을 신약 개발 관점에서 평가합니다.
워크플로우
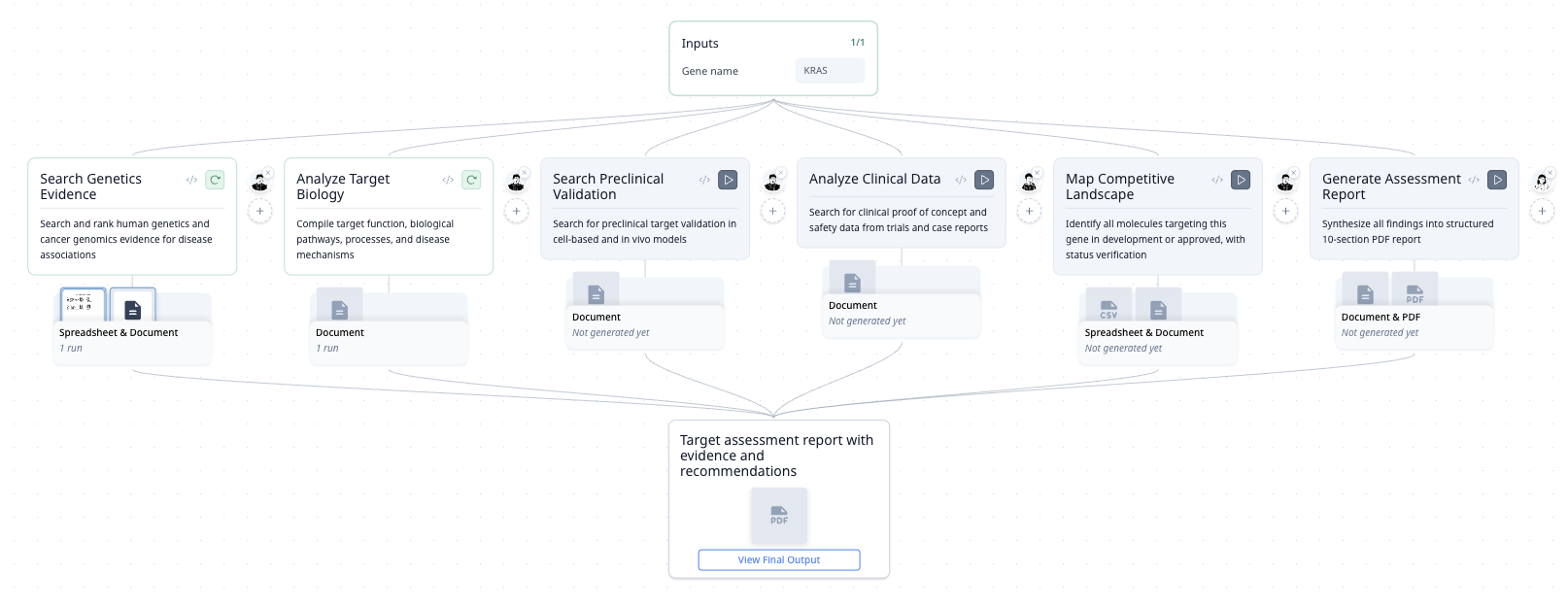
| 단계 | 수행 내용 |
|---|---|
| 유전학 근거 | GWAS, ClinVar, COSMIC를 검색하고 통계적 강도별로 연관성을 순위화합니다 |
| 타겟 생물학 | UniProt과 문헌에서 기능 및 경로 데이터를 추출합니다 |
| 검증 데이터 | PubMed에서 전임상 세포 및 in vivo 모델 연구를 찾습니다 |
| 임상 근거 | ClinicalTrials.gov에서 유효성과 안전성 신호를 조회합니다 |
| 경쟁 환경 | 개발 중인 모든 분자를 매핑합니다 — 화합물, 회사, 단계, 활성 상태 |
| 전략적 평가 | 역학, 모달리티 적합성, 기회 격차, 위험을 종합합니다 |
| PDF 보고서 | 인라인 인용이 포함된 구조화된 10개 섹션 평가서를 생성합니다 |
구축 방법
"I need a disease-agnostic target assessment agent. Given a gene, evaluate genetics evidence, target biology, preclinical validation, clinical data, safety, patient population, competitive landscape, modality, opportunity, and key challenges."
제약 과학자의 표준 평가 체크리스트 — 그대로 붙여넣기. MorphMind가 이를 실시간 데이터베이스 쿼리가 포함된 7단계 연구 파이프라인으로 전환했습니다.
챗봇보다 나은 이유
ChatGPT에 "BRAF를 암 타겟으로 평가해 줘"라고 하면 일반적인 에세이를 받습니다. 문제는:
- 경쟁 환경을 검증할 수 없습니다 — 화합물과 회사를 나열하지만, 최신인지 학습 데이터에서 만들어진 것인지 알 수 없습니다. 이 에이전트는 ClinicalTrials.gov를 실시간으로 조회하므로 모든 항목에 검증 가능한 출처가 있습니다.
- 유전학 섹션은 잘못 보이지만 생물학 섹션은 괜찮습니다 — 챗봇에서는 다시 프롬프트하면 완전히 새로운 답변을 받습니다. 여기서는 다른 데이터베이스 필터로 유전학 단계만 다시 실행합니다.
- 매 타겟마다 같은 10점 체크리스트를 사용합니다 — 하지만 챗봇은 그 구조를 기억하지 못합니다. 다음 주에는 다른 형식, 누락된 섹션, 다른 깊이를 받습니다. 워크플로우 에이전트는 매번 같은 파이프라인을 일관된 구조로 실행합니다.
공개 또는 독점 데이터 소스를 추가할 수도 있습니다 — 에이전트에게 특정 API 키를 사용하도록 지시하면 됩니다. 같은 워크플로우가 공개 데이터를 사용하는 학술 연구실과 라이선스 데이터베이스를 사용하는 제약 팀 모두에서 작동합니다.
| 문제 | 워크플로우 접근 방식 |
|---|---|
| 경쟁 환경이 오래되었거나 지어낸 것일 수 있음 | 검증 가능한 항목이 포함된 실시간 ClinicalTrials.gov 쿼리 |
| 한 섹션이 잘못되면 전체 보고서 재생성 | 해당 섹션만 재실행, 나머지 유지 |
| 요청할 때마다 형식 변경 | 매 실행마다 동일한 10개 섹션 구조 |
| 공개 데이터베이스에 제한됨 | 대화를 통해 독점 소스 추가 |
프롬프트 예시
Assess BRAF as a cancer target. Provide the full 10-section evaluation.
What is the competitive landscape for TP53-targeting therapies? Include compound, company, stage, and active status.
Evaluate WRN as a synthetic lethal target in MSI-high cancers. What modality fits best?
자주 묻는 질문
AI가 제약 회사를 위해 약물 타겟을 평가할 수 있나요?
이 에이전트는 제약 탐색 팀이 사용하는 표준 타겟 평가 워크플로우를 자동화합니다. 실제 생의학 데이터베이스 — GWAS, ClinVar, ClinicalTrials.gov, ChEMBL — 를 조회하고 인라인 인용이 포함된 구조화된 10개 섹션 보고서를 생성합니다.
AI 약물 타겟 평가는 수동 검토와 비교하면 어떤가요?
수동 타겟 평가는 일반적으로 510개 데이터베이스를 대상으로 팀이 12주가 걸립니다. 이 에이전트는 일관된 구조로 몇 분 만에 동일한 평가를 실행합니다. 결과물은 탐색적 읽기가 아닌 go/no-go 결정을 위해 설계되었습니다.
이 에이전트에서 독점 데이터 소스를 사용할 수 있나요?
네. 키를 제공하여 에이전트에게 모든 API에 연결하도록 지시하세요. 에이전트가 통합을 처리합니다 — 구성 파일이나 코드 변경이 필요 없습니다. 같은 에이전트가 공개 데이터베이스와 라이선스 데이터셋 모두에서 작동합니다.