Target Discovery & Validation Agent
Evaluate any gene target for drug discovery — genetics, biology, competitive landscape — in one run.
The Workflow
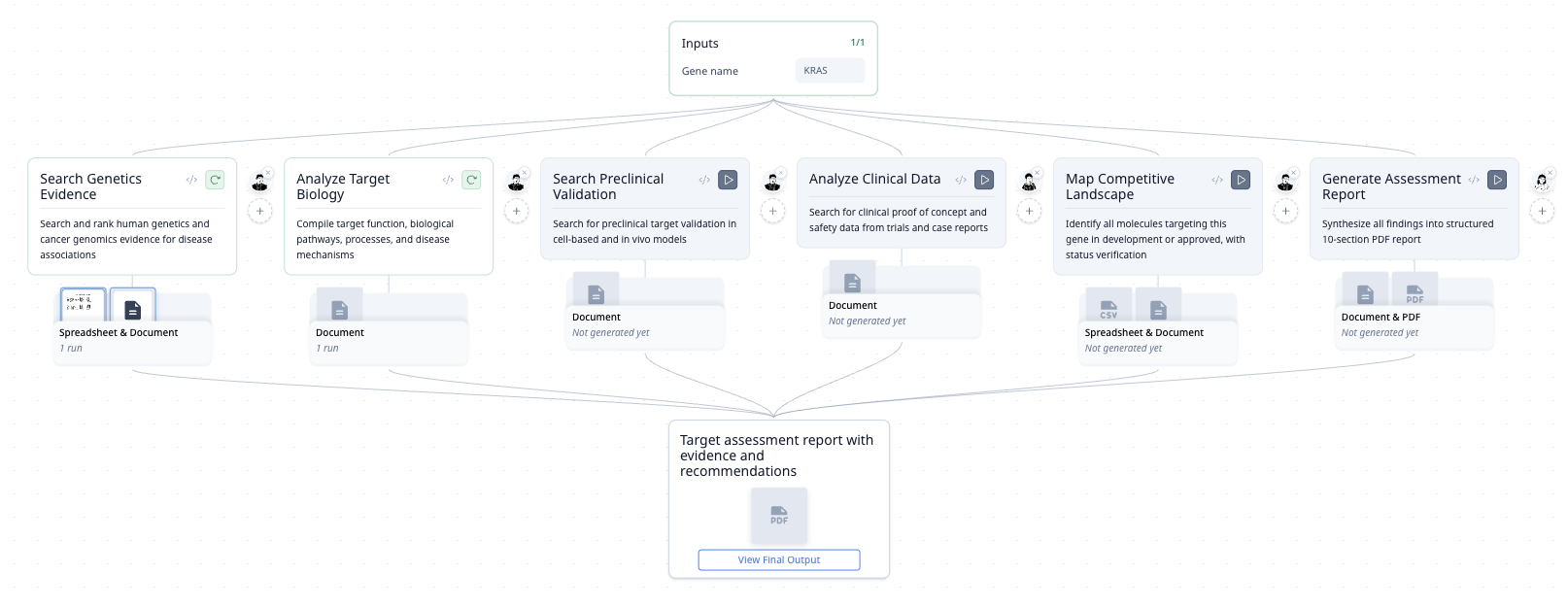
| Step | What It Does |
|---|---|
| Genetics Evidence | Searches GWAS, ClinVar, COSMIC — ranks associations by statistical strength |
| Target Biology | Extracts function and pathway data from UniProt and literature |
| Validation Data | Finds preclinical cell and in vivo model studies from PubMed |
| Clinical Evidence | Queries ClinicalTrials.gov for efficacy and safety signals |
| Competitive Landscape | Maps all molecules in development — compound, company, stage, active status |
| Strategic Assessment | Synthesizes epidemiology, modality fit, opportunity gaps, and risks |
| PDF Report | Generates a structured 10-section assessment with inline citations |
How It Was Built
"I need a disease-agnostic target assessment agent. Given a gene, evaluate genetics evidence, target biology, preclinical validation, clinical data, safety, patient population, competitive landscape, modality, opportunity, and key challenges."
A pharma scientist's standard evaluation checklist — pasted in as-is. MorphMind turned it into a 7-step research pipeline with live database queries.
Why This Works Better Than a Chatbot
Ask ChatGPT to "assess BRAF as a cancer target" and you get a general essay. The problem:
- You can't verify the competitive landscape — it lists compounds and companies, but you don't know if they're current or hallucinated from training data. This agent queries ClinicalTrials.gov live, so every entry has a verifiable source.
- The genetics section looks wrong but the biology section is fine — in a chatbot, you re-prompt and get a completely new answer. Here, you re-run just the genetics step with different database filters.
- You use the same 10-point checklist for every target — but the chatbot doesn't remember the structure. Next week you get a different format, missing sections, different depth. A workflow agent runs the same pipeline every time, with consistent structure.
You can also add any data source — public or proprietary — by telling the agent to use a specific API key. The same workflow works for academic labs on public data and pharma teams with licensed databases.
| The Problem | Workflow Approach |
|---|---|
| Competitive landscape may be outdated or invented | Live ClinicalTrials.gov query with verifiable entries |
| One wrong section means regenerating the whole report | Re-run just that section, keep the rest |
| Format changes every time you ask | Same 10-section structure on every run |
| Stuck with public databases | Add proprietary sources through conversation |
Example Prompts
Assess BRAF as a cancer target. Provide the full 10-section evaluation.
What is the competitive landscape for TP53-targeting therapies? Include compound, company, stage, and active status.
Evaluate WRN as a synthetic lethal target in MSI-high cancers. What modality fits best?
Frequently Asked Questions
Can AI evaluate drug targets for pharma?
This agent automates the standard target assessment workflow used by pharma discovery teams. It queries real biomedical databases — GWAS, ClinVar, ClinicalTrials.gov, ChEMBL — and produces a structured 10-section dossier with inline citations.
How does AI drug target assessment compare to manual review?
Manual target assessment typically takes a team 1–2 weeks across 5–10 databases. This agent runs the same evaluation in minutes with consistent structure. The output is designed for go/no-go decisions, not exploratory reading.
Can I use proprietary data sources with this agent?
Yes. Tell the agent to connect to any API by providing the key. It handles the integration — no configuration files or code changes needed. The same agent works with public databases and licensed datasets.