PDF 无障碍修复器
让您的 PDF 对屏幕阅读器友好——只需几分钟,而非几小时。
工作流
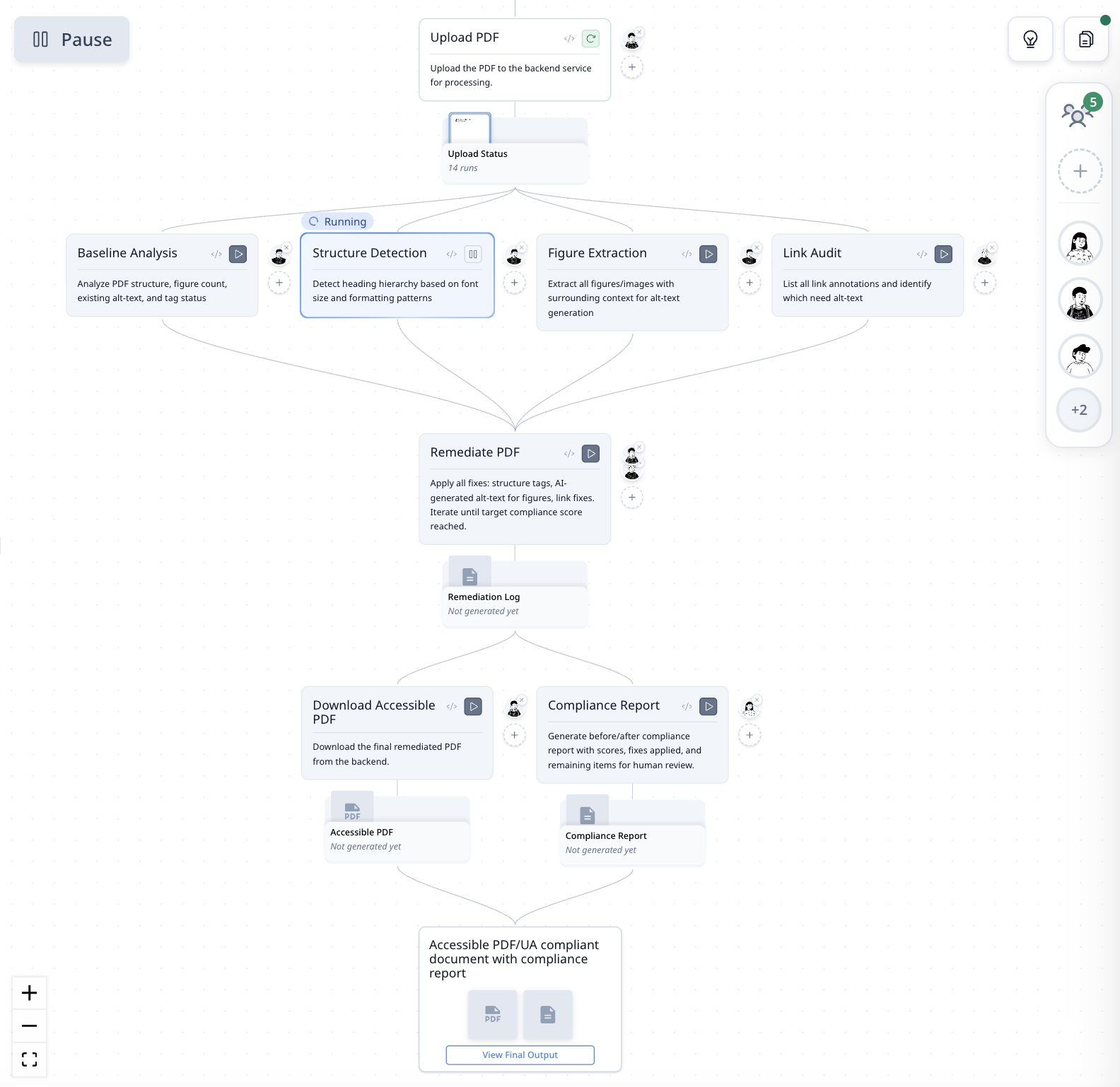
| 步骤 | 功能说明 |
|---|---|
| 上传 PDF | 将 PDF 发送到后端服务进行处理 |
| 基线分析 | 分析结构、图片数量、现有替代文本和标签状态 |
| 结构检测 | 根据字体大小和格式检测标题层级 |
| 图片提取 | 提取所有图片及其周围上下文,用于生成替代文本 |
| 链接审计 | 列出所有链接注释,标记缺少替代文本的链接 |
| 修复 PDF | 应用修复:结构标签、AI 生成的替代文本、链接修复——迭代直到达到合规目标 |
| 下载无障碍 PDF | 下载最终修复后的文档 |
| 合规报告 | 生成修复前后的评分、应用的修复和需要审核的剩余项目 |
如何构建的
"Make this PDF accessible with WCAG 2.1 compliance."
一句话加上一个文件上传。MorphMind 构建了 8 步修复管线,将其连接到后端无障碍服务,并配置了合规评分——可以处理任何 PDF。
为什么比聊天机器人更好
ChatGPT 和 Claude 等工具可以处理 PDF——但它们将整个文件作为一次性处理。您得到一个修改后的 PDF,却看不到具体更改了什么。问题在于:
- 您无法分辨修复了什么 — AI 返回一个文件,但您不知道它是否处理了标题、替代文本、链接标签,还是三者都处理了。如果合规审计仍然失败,您只能猜测遗漏了哪个部分。
- 没有迭代 — 如果一张图片的替代文本有误,您需要重新上传并重新处理整个文档。无法只修复一张图片而不重新运行所有内容。
- 没有合规评分 — 您做了修改,只能期望足够了。手动 WCAG 审计既繁琐又容易出错。该 Agent 运行修复前后的合规检查,并精确告诉您哪些通过了,哪些还有问题。
| 问题 | 工作流方式 |
|---|---|
| 一次性处理——看不到修复了什么 | 每个步骤(结构、图片、链接)独立运行并报告 |
| 一个替代文本有误?重新处理整个文件 | 只重新运行图片提取步骤 |
| 没有合规验证 | 修复前后评分,逐项通过/未通过 |
| 边缘情况需要手动 Adobe Acrobat 标记 | 自动修复迭代直到达标,标记剩余问题 |
使用方法
第 1 步:上传您的 PDF

Make this PDF accessible with WCAG 2.1 compliance
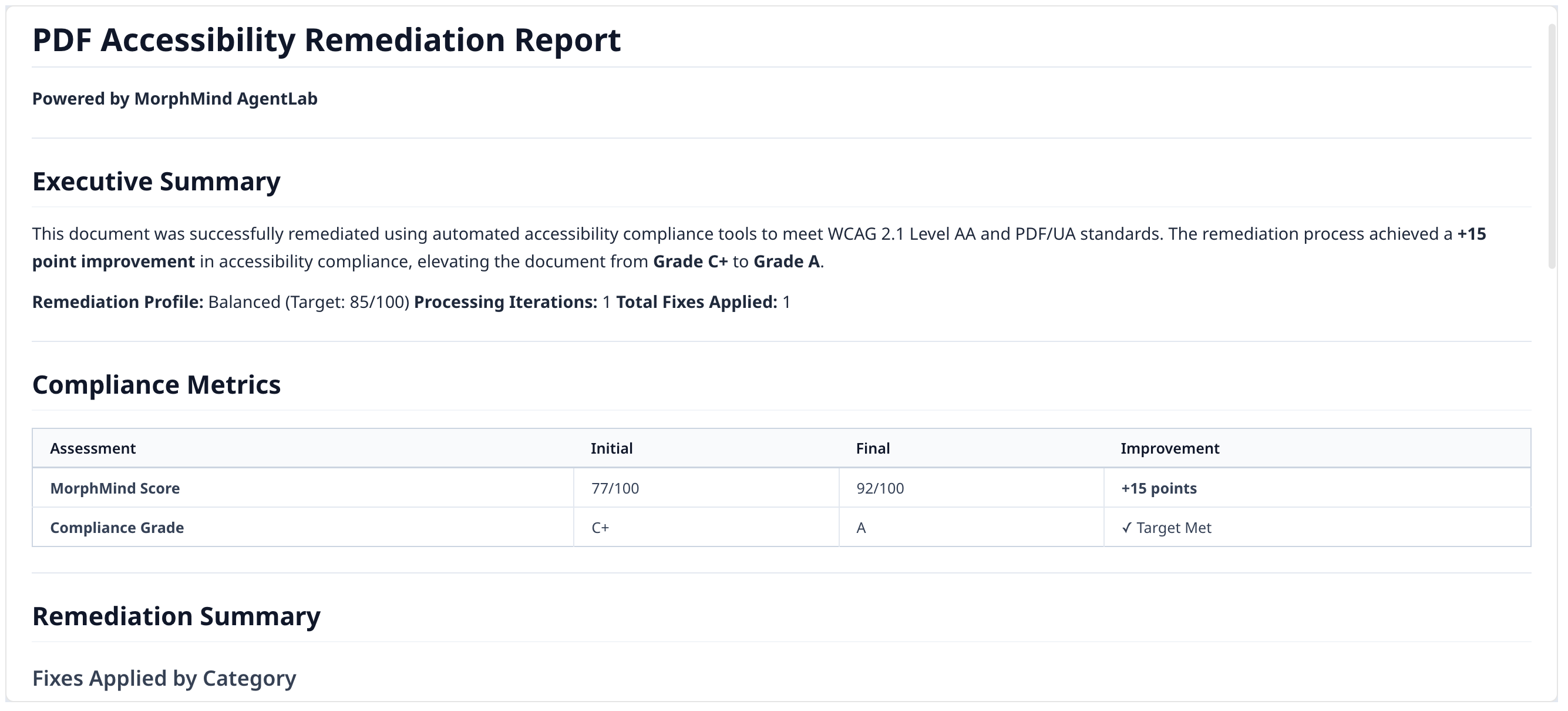
第 2 步:审核修复报告
Agent 运行所有步骤并返回合规报告,显示初始评分与最终评分以及每项修复内容。
第 3 步:下载您的无障碍 PDF
修复后的 PDF 已应用所有无障碍标签——标题、替代文本、链接标签、阅读顺序。
修复前后对比
修复前: 通用的 <Figure> 标签。屏幕阅读器无法解读内容。

修复后: 正确的 <H1>、<P>、<Formula> 标签——全部附带替代文本。

示例提示
Make this PDF accessible with WCAG 2.1 compliance
Check this document's accessibility score and tell me what's missing
Generate alt-text for all figures in this PDF
常见问题
AI 能让 PDF 符合 WCAG 2.1 标准吗?
该 Agent 应用结构标签、为图像和公式生成替代文本、修复链接标签,并根据 WCAG 2.1 和 PDF/UA 标准进行验证。它会生成合规评分,并逐项列出已修复和需要人工审核的内容。
AI 如何为 PDF 图片生成替代文本?
该 Agent 提取每张图片及其周围的上下文(标题、正文),并生成描述性替代文本,捕捉图片所传达的信息——而不仅仅是它的外观。
自动化 PDF 无障碍修复和手动标记一样好吗?
该 Agent 处理重复性的结构工作——标题标签、阅读顺序、图片替代文本——这些构成了修复工作的大部分。复杂情况(装饰性与信息性图像、不寻常的布局)会在合规报告中标记供人工审核。
开源
自行托管或参与底层工具的贡献: